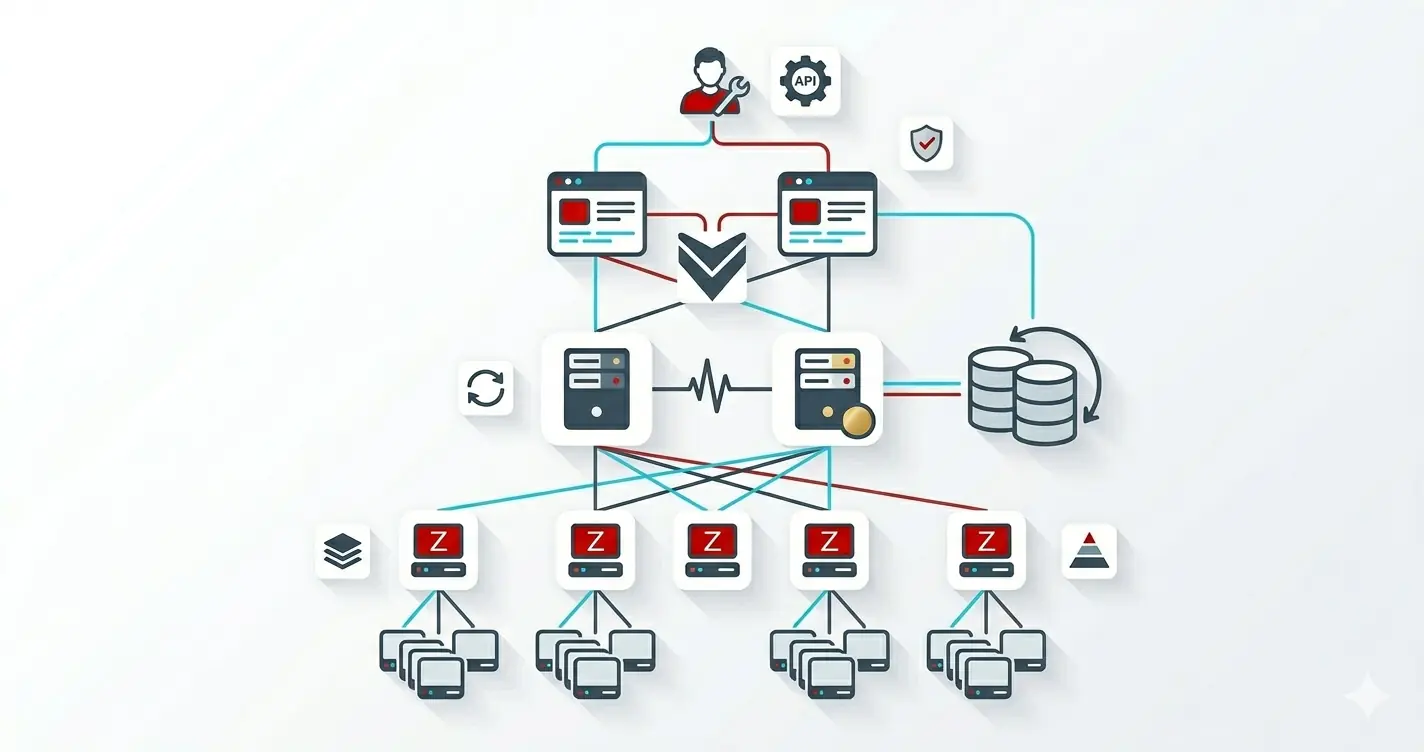
Why Two Servers, Not One
A single zabbix_server is a single point of failure for the entire monitoring estate. The first time it crashes during a kernel patch (or a misbehaving discovery rule, or an out-of-disk on /var/lib/postgresql), every alert in your environment goes silent until you bring it back up. By then, whatever caused you to need the alerts has had a comfortable head start.
Zabbix 6.0 introduced native HA at the server tier. The mechanism is simpler than most people expect: every zabbix_server daemon writes a heartbeat row into the database's ha_node table; exactly one is elected active; the others sit in standby, polling the same table on a 5-second cadence. When the active server stops heartbeating, a standby promotes itself within roughly 60 seconds and starts processing.
Three properties this gives you that the single-node deploy does not:
- Restartable for maintenance. Patching the active server is a
systemctl stop zabbix-serverfollowed by 60 seconds; the standby takes over, your alerts keep firing, you reboot, the server comes back as the new standby. - No shared state to coordinate. Both servers read the same database. There is no
keepalived, no virtual IP, no DRBD replication, nopcscluster. The frontend looks at theha_nodetable and queries the active server. - Asymmetric capacity is fine. The standby server can be smaller; it does almost no work until promoted. You don't need two identical hosts.
Primary Zabbix Server Setup
As I mentioned on my previous post, I'll be using Ubuntu 24.04 as the base operating system.
This guide assumes that you are capable of deploying a ubuntu server on your own. If not, please follow this guide before proceeding.
1. Install Zabbix Repository
The first step is to add the zabbix repository to the server. We'll be using version 7.4 for this installation.
Check out the zabbix documentation for the current version.
Download the package from zabbix
We'll use wget to download the package for our Operating System, Ubuntu 24.04
wget https://repo.zabbix.com/zabbix/7.4/release/ubuntu/pool/main/z/zabbix-release/zabbix-release_latest_7.4+ubuntu24.04_all.deb
Install the package
We'll use dpkg to to install the package we downloaded
sudo dpkg -i zabbix-release_latest_7.4+ubuntu24.04_all.deb
Update the packages
Update the repository to make the packages available
sudo apt update -y
2. Install zabbix server
We'll install the following components:
zabbix-server-pgsqlzabbix-sql-scriptszabbix-agent
sudo apt -y install zabbix-server-pgsql zabbix-sql-scripts zabbix-agent
Edit the config file
We need to edit the config file located at /etc/zabbix/zabbix_server.conf and configure DBHost,DBName,DBUser,and DBPassword.
Towards the bottom of the same config file we need to configure HANodeName and NodeAddress to enable HA.
The values in my config file look like this:
The value of HANodeName must be unique across all Zabbix Servers
# database server IP
DBHost=10.0.0.20
# Database name
DBName=zabbix
# database user
DBUser=zabbix
# database password
DBPassword=zabbix
# database port
DBPort=5432
--------------- snip -------------------
####### High availability cluster parameters #######
# hostname of zabbix server. This value must be unique
HANodeName=zabbix01
# IP:Port of the server
NodeAddress=10.0.0.21:10051
3. Import DB Schema
Copy Schema to ZabbixDB server
Now that we have the zabbix server setup, we need to import the initial database schema into the database. Right now, we only have the server configured with a blank database. We'll copy the file located at /usr/share/zabbix/sql-scripts/postgresql/server.sql.gz to the zabbix database server 10.0.0.20 using scp:
scp /usr/share/zabbix/sql-scripts/postgresql/server.sql.gz [email protected]:/home/administrator
Import Database Schema
Now we need to connect to the zabbixDB 10.0.0.20 and import the schema into PostgrSQL. We'll use zcat to decompress the file and create the tables using the zabbix user we created during the zabbix database setup. On the Zabbix Database server, run:
This will take a few minutes to complete
zcat /home/administrator/server.sql.gz | sudo -u zabbix psql zabbix
Enable and restart the service
To start the zabbix server, we need to restart the zabbix-server service, but before restarting the service, let's enable it so it automatically restarts on reboot.
Enable service
sudo systemctl enable zabbix-server
Restart service
sudo systemctl restart zabbix-server
Backup Server setup
To set up the backup server, just follow the steps 1-3 and modify the configuration files to reflect the new configuration.
Make sure your servers have a static IP address. Below is the /etc/netplan/*.yaml config I'm using
10.0.0.21: Zabbix server address (Primary)10.0.0.22: Zabbix server address (Backup)10.0.0.1: Gateway10.0.0.200: Internal DNS server
network:
version: 2
renderer: networkd
ethernets:
eth0:
addresses:
- 10.0.0.21/24
routes:
- to: default
via: 10.0.0.1
nameservers:
addresses: [10.0.0.200]
search: [ns01.example.com]
Verifying the HA Election
Before you build the frontend on top, confirm both servers see each other and agree on who is active. From either server (or the database host), with psql access to the zabbix database:
sudo -u zabbix psql zabbix -c "SELECT name, status, lastaccess FROM ha_node ORDER BY status DESC;"
You want to see two rows: one with status=3 (active), one with status=0 (standby), and lastaccess updating every few seconds when you re-run the query. If both rows show status=3, you have a split-brain stuck-election bug check that both servers can reach the database and that HANodeName is unique per server.
Test the Failover Before You Need It
The whole point of this build is the failover. Schedule fifteen minutes to actually trigger one before users depend on the cluster:
- On the active server,
sudo systemctl stop zabbix-server. - Watch the
ha_nodequery above on a 1-second loop. Within 60 seconds, the standby'slastaccesskeeps advancing while the active row stops; then the standby flips tostatus=3. - Bring the original active server back with
systemctl start zabbix-server. It rejoins as standby; no manual intervention. - Optional: trigger the failover the harsh way too power-cycle the active VM. Same observable result, more confidence the next outage handles itself.
A failover that nobody has ever exercised is not a failover; it is a hope.
Next in the Series
The frontend post builds the nginx + PHP container that talks to the database (for HA-state lookup) and to the active server (for the API). Read it next, then continue to the proxy post when you are ready to scale collection out from the servers.

![Zabbix Log File Monitoring with log[] and logrt[]](/Images/Posts/zabbix-log-monitoring.webp)